딥러닝 개념(Deep Learning)
- IT정보
- 2022. 3. 28.
딥러닝(Deep Learning)에 대한 열기가 뜨겁다. 알파고 쇼크 이후 인공지능이라는 말과 머신러닝, 딥러닝이라는 말은 거의 같은 의미로 쓰이고 있다. 하지만 이들은 엄연히 다른 개념이다. 인공지능 개념에서 살펴보았지만 이들 사이의 관계를 다시 한번 살펴보자.
인공지능이 가장 넓은 개념이며, 인공지능의 중요한 구현 방법 중 하나가 머신러닝(Machine Learning)이고, 머신러닝 중 하나의 방법론이 딥러닝(Deep Learning)이다. 딥러닝은 또한 인공신경망(Artificial Neural Network)의 한 종류이다. 즉, 인공지능 ⊃ 머신러닝 ⊃ 인공신경망 ⊃ 딥러닝 관계가 성립한다.

딥러닝의 성능을 세상에 알린 3대 사건
음성인식 정확도 향상
딥러닝에 대해서 자세히 알아보기 전에 딥러닝이 유행하게 된 몇 가지 중요한 사건들을 살펴보자.
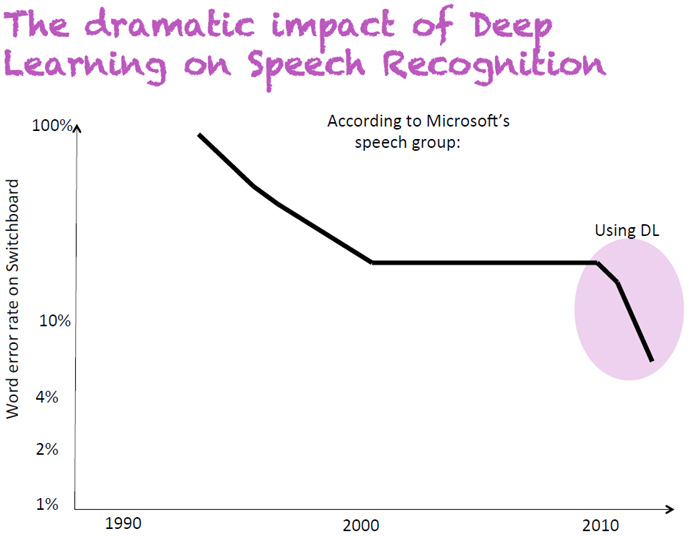
먼저, 마이크로소프트사의 음성인식 분야를 살펴보자. 아래 자료를 보면 1990년대는 음성인식 오류율이 꾸준히 줄었으나 2000년부터 2010년까지 10년간 전혀 발전이 없었다. 그러다가 딥러닝(DL, Deep Learning)을 도입하고 오류율이 급격히 줄어든 것을 볼 수 있다. 이를 통해 딥러닝의 강력한 힘을 깨달았다고 한다.
이미지넷 정확도 향상
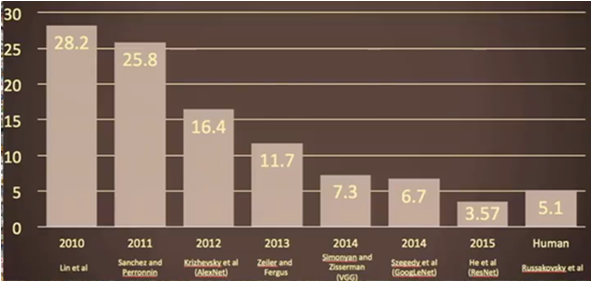
다음으로 이미지 인식 분야의 경진대회인 이미지넷(IMAGENET)에서 일어난 사건을 살펴보자. 이미지넷 대회는 사진을 보고 사진속의 대상을 인식하는 대회로서, 2011년까지 인식 오류율이 26%에 가까운 상황이었으며, 사람들은 1년 내내 노력해서 1% 올리기가 어려운 상황이었다고 한다. 2012년 캐나다 토론토 대학교의 수퍼비전팀(SuperVision)이 딥러닝 방식인 deep convolutional neural network을 적용한 알렉스넷(AlexNet)으로 16.4%라는 경이로운 오류율을 기록했다. 1년만에 거의 10% 가까이 오류율을 끌어올린 이 사건을 보고 이미지 인식분야의 많은 사람들이 거의 경악 수준으로 놀랐다고 한다. 그 후 이미지넷에 참여하는 모든 참가자가 딥러닝 방식을 적용했으며, 이미 2015년에 사람의 오류율(5.1%)보다 더 뛰어난 3.57%의 오류율을 달성했다. 참고로, 수퍼비전팀을 이끌었던 사람이 캐나다 토론토 대학교의 인공지능 대부 제프리 힌튼 교수(Geoffrey Hinton)이다.
비지도학습을 통한 이미지 인식 성공
세번째는 비지도학습(Unsupervised Learning)을 이용하여 이미지를 인식하는 것이 가능함을 보여준 사건이다. 2012년 구글에서 유튜브(Youtube) 동영상을 캡쳐한 화면(200x200) 1000만개를 학습시켜서 고양이, 인간 등을 인식시키는 데 성공했다. 지금까지는 지도학습(Supervised Learning)을 이용하여 이미지를 인식시켰으나 이번 사건은 비지도학습을 통한 학습의 가능성을 확인한 중요한 사건이라고 한다. 이 프로젝트는 앤드류 응(Andrew Ng) 교수가 주도했으며, 16,000개의 CPU 코어를 가지고 9개층 10억개 파라미터(parameter)를 가진 인공신경망을 3일간 학습시켰다. 아래 그림은 고양이를 인식시킨 사진으로 유명한데, 실제 발표된 논문을 보면 인간의 얼굴에 대한 인식 정확도가 81.7%, 인간의 몸은 76.7%이고 정작 고양이 인식 정확도는 74.8%였다.

이러한 3대 사건은 딥러닝을 성능을 확인시켜 주었으며, 사회 여러 분야에서 딥러닝을 활발히 이용하는 계기가 되었다. 이제 딥러닝이 무엇인지 알아보자.
딥러닝 개념
왜 '인공신경망'이 아닌 다른 이름이 필요했을까?
딥러닝(Deep Learning)은 최근 유행하기 시작한 인공신경망(Artificial Neural Network)을 일컫는 말이다. 그냥 '인공신경망'이라는 이름을 써도 되는데 굳이 다른 이름을 쓰고 있다. 그 이유가 있다.
인공신경망은 두뇌의 신경세포, 즉 뉴런이 연결된 형태를 모방한 모델이다. 하나의 뉴런을 모델링한 퍼셉트론(Perceptron)과 이를 여러 층으로 연결한 다층 퍼셉트론(MLP, Multi-Layer Perceptron)이 있으며, 이를 학습시키기 위해서 역전파 알고리즘(Backpropagtion Algorithm)이 나왔다.(딥러닝을 이해하기 위해서는 먼저 인공신경망을 이해할 필요가 있다. 이를 위해 필자의 다른 글 인공신경망 개념을 먼저 살펴볼 것을 추천한다.)

인공신경망에서 이용했던 다층 퍼셉트론(MLP, Multi-Layer Perceptron)은 근본적인 한계를 가지고 있었다. 복잡한 문제를 해결하기 위해서는 신경망의 층수를 여러층 쌓은 모델을 이용해야 하는데, 깊은 층수를 쌓을 경우 역전파(Backpropagtion) 학습과정에서 데이터가 사라져 학습이 잘 되지 않는 현상인 '사라지는 경사도(Vanishing Gradient)' 문제가 있었다. 또한 학습한 내용은 잘 처리하나 새로운 사실을 추론하는 것, 새로운 데이터를 처리하는 것을 잘하지 못하는 한계도 있었다. 이로 인해 오랜 기간 동안 인공신경망은 이용하기 어려워 거의 몰락에 가까운 상황에 이르렀으며 '인공신경망'이라는 단어는 사용하면 안되는 단어가 되었다고 한다.
"90년대 초부터 인공신경망 분야가 완전히 몰락을 했습니다. 미국, 일본, 유럽에서 인공신경망이란 단어 자체를 사용해서는 안되는, 그 단어를 사용하면 정부 과제를 받을 수 없을 정도로..."

인공신경망의 이러한 한계는 2000년이 넘어서야 극복할 수 있는 방법이 나왔다. 캐나다 토론토 대학의 제프리 힌튼(Geoffrey Hinton) 교수는 2006년에 깊은 층수의 신경망 학습시 사전 학습(Pretraining)을 통해서 학습함으로써 Vanishing Gradient 문제를 해결할 수 있음을 밝혔다. 또한 새로운 데이터를 잘 처리하지 못하는 문제는 학습 도중에 고의로 데이터를 누락시키는 방법(dropout)을 사용하여 해결할 수 있음을 2012년에 밝혔다.
이런 방법을 사용하여 기존의 인공신경망의 한계를 뛰어넘은 인공신경망을 '딥러닝'이라는 새로운 이름으로 부르기 시작했다. '인공신경망'이라는 이름이 가진 부정적인 인식에서 벗어나기 위해서였다.
"기존 인공신경망의 한계를 뛰어넘은 인공신경망을 '딥러닝'이라고 이름을 새로 붙인겁니다. 리브랜딩 한 겁니다. 왜냐, 인공신경망이 이미지가 너무 안좋으니까..."
딥러닝이 최근 유행한 데는 이러한 한계 극복과 함께 다양한 요인이 작용했다. 여기에는 세가지 요인이 있는데, 첫번째는 위에서 살펴본 것과 같이 기존의 인공신경망의 한계를 극복할 수 있는 알고리즘의 개발, 두번째는 오랜 정보화의 결과로 신경망 학습에 필요한 막대한 학습데이터가 축적됐다는 점, 세번째는 신경망을 이용한 학습과 계산에 적합한 그래픽 처리장치(GPU, Graphics Processing Unit) 등 하드웨어의 발전이다.

여기서 잠깐, 깊은('Deep') 학습(Learning)이 있으니까 얕은('Shallow') 학습도 있지 않을까 궁금한 사람이 있을 것이다. 실제 얕은 학습(Shallow Learning)이 언제 끝나고 딥러닝이 언제 시작하는지에 대한 명확한 기준이 있는 것은 아닌 것 같다.(참고13) 통상 은닉층이 1개인 신경망을 얕은 신경망, 은닉층이 2개 이상인 신경망을 깊은 신경망이라고 한다.(참고14, 15)

대표적인 딥러닝 모델, CNN, RNN
대표적인 딥러닝 모델은 CNN과 RNN이다. 여기서는 간략히 알아보자.
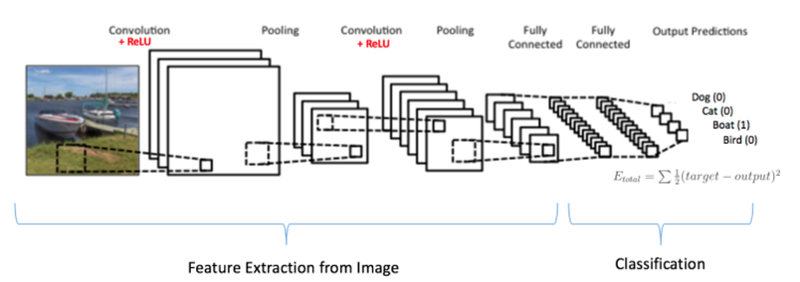
CNN(Convolutional Neural Network)은 이미지를 인식하는 데 주로 사용된다. 같은 이미지라 하더라도 위치가 변하거나 방향이 바뀌거나 이미지가 왜곡되는 등 다양한 경우가 있을 수 있고, 이러한 변화에 관계없이 인식하기 위해 Convolution과 Pooling과정을 반복 적용하여 이미지에서 추상화된 정보를 추출한다.
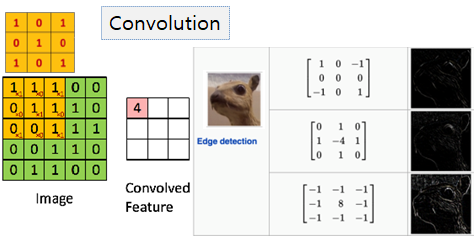
Convolution은 여러가지 필터(filter)를 사용하여 이미지의 특징을 도출한다.
Pooling은 이미지의 특징은 유지하면서 차원(dimension)을 줄이는 역할을 한다.

RNN(Recurrent Neural Network)은 음성과 글자 등 순차적인(Sequential) 정보를 인식하는 데 주로 사용된다. 아래 그림의 RNN은 이전 상태의 상태값(s)이 다음 계산의 입력으로 들어가서 결과에 영향을 미치는 구조로 되어 있다. 이는 단어, 문장 등을 인식할 때 앞의 단어와 글자를 참고하여 인식할 필요가 있기 때문이다. 예를들어 "Hell" 다음은 "o"를 위치시켜서 "Hello"라는 단어를 완성시키는 데 RNN 모델을 이용할 수 있을 것이다.
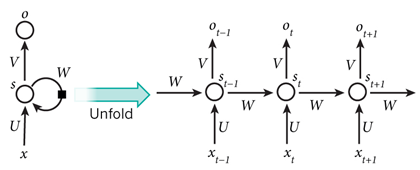
RNN은 음성인식, 기계번역, 이미지 설명 등 여러 곳에 활용되는데, 아래 그림은 RNN 두개를 사용하여 기계번역기를 만드는 방법을 간략히 제시하고 있다. 영어 문장을 RNN 모델에 입력하여 숫자로 인코딩한뒤, 인코딩 된 숫자를 두번째 RNN에 거꾸로 입력하여 스페인어 문장을 출력하도록 학습시키는 방식으로 기계번역기를 말들 수 있을 것이다.(참고18)

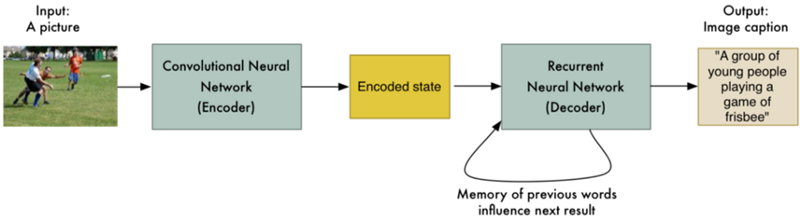
기계번역 모델을 조금 더 확장하여 CNN과 RNN을 동시에 활용하면 사진 속의 상황을 문장으로 설명하는 모델도 만들 수 있다. 아래 그림에서 이미지를 CNN 모델에 입력하여 숫자로 인코딩한 뒤, 인코딩 된 숫자를 RNN 모델에 입력하여 사진 속 상황을 설명하는 문장을 출력하도록 학습시킬 수 있다.(참고18)
아래 그림처럼 사진 속에 있는 다양한 사물들을 인식하는 방식으로도 응용할 수 있다.

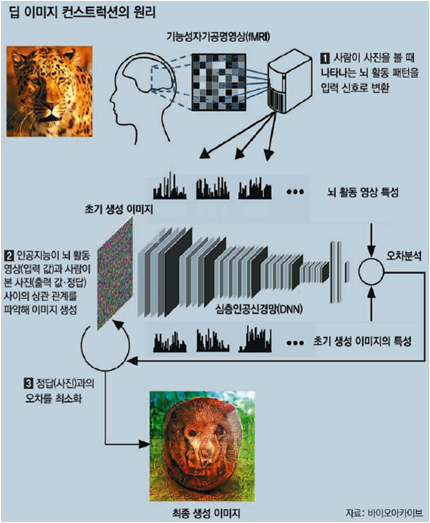
딥러닝을 활용한 흥미로운 사례를 하나 살펴보자. 사람이 눈으로 본 장면을 인공지능이 그대로 그려주는 모델을 딥러닝을 이용해서 구현한 것이다. 이를 위해, 사진이나 그림 등을 볼 때 나타나는 뇌의 활동 패턴을 fMRI로 측정하고, fMRI 이미지 픽셀 값들을 디지털로 전환한 뒤 심층신경망(DNN, Deep Neural Network)에 입력한다. 그리고 직접 본 장면 사진을 출력(정답) 데이터로 학습시키면 인공지능은 입력값(뇌 활동 패턴을 나타내는 fMRI 이미지)과 출력값(정답 사진) 사이의 상관관계를 스스로 학습하여 사람이 봤던 것과 유사한 이미지를 생성해 내게 된다.(참고19)
* 딥러닝(Deep Learning)은 심층신경망(DNN, Deep Neural Network)이라고도 한다.(참고15)
딥러닝의 강점, 약점
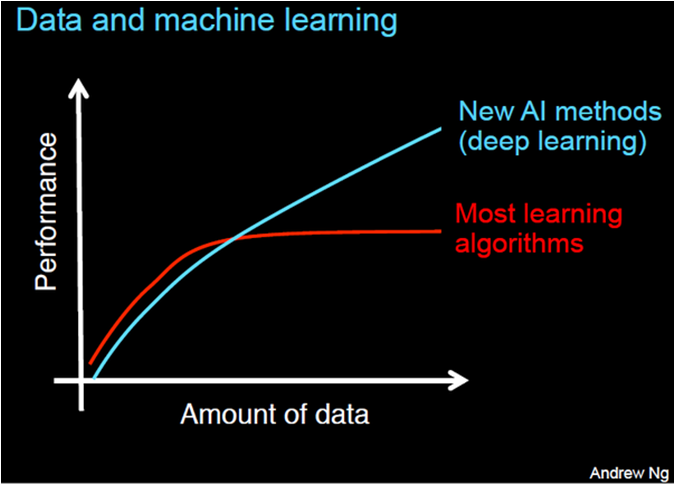
딥러닝은 데이터가 많아지면 많아질수록 성능이 더 좋아진다고 한다. 앤드류 응(Andrew Ng) 교수에 따르면, 보통의 머신러닝 알고리즘은 데이터가 많아지더라도 일정 시점 이후에는 성능이 그다지 올라가지 않는데, 딥러닝 알고리즘은 데이터가 증가함에 따라 성능도 지속적으로 향상된다고 한다.
딥러닝은 머신러닝이 기본적으로 가지고 있는 약점도 가지고 있다. 머신러닝과 딥러닝 알고리즘은 환경변화에 따라 지속적으로 재학습이 필요하다.
"아직까지 딥러닝이 가장 못하는 것 중 하나가 실시간 학습입니다. 현재의 딥러닝 기계는 1,000가지 물체를 알아봅니다. 그런데 이때 새로운 물체 하나를 추가로 학습하려면 이미 알고 있는 1,000가지는 잊어버려야 해요. 근데 인간은 그렇지 않습니다."
통상은 전체를 한꺼번에 학습시켜야 하지만 특수한 경우에는 새로 생긴 데이터만 학습시키는 방법이 이용되기도 한다. 여기서 전체를 한꺼번에 학습시키는 것을 Batch Learning이라고 하고, 새로 생긴 데이터만 따로 학습시키는 방법을 Incremental Learning이라고 한다.
예를들어, 딥러닝 모델을 사용하여 보행자, 차, 오토바이, 트럭 사진을 구분하는 작업을 수행한다고 하자. 아래와 같이 입력층, 두개의 은닉층, 출력층으로 구성된 인공신경망을 이용하여 사진 데이터를 입력으로 하고 출력 노드는 각각 보행자, 차, 오토바이, 트럭으로 하는 모델을 학습시킨다. 학습을 완료하고 4가지 물체를 잘 인식하는 모델을 만든 뒤, 이 모델에 고양이도 추가로 인식하도록 해보자. 출력 노드에 고양이 노드가 추가되면 신경망 속의 모든 노드들과 파라미터들에 영향을 주기 때문에 전체를 다시 학습시킬 수 밖에 없다. 왜냐하면, 고양이 노드 출력에 영향을 주는 입력값은 고양이가 있는 사진만이 아니고 다른 사진들도 모두 영향을 미친다. 즉, 보행자, 차, 오토바이, 트럭 사진이 입력으로 왔을 때 이것은 고양이 출력 노드와 관계가 없는 것이 아니고, 이러한 사진들이 고양이 출력노드에 "관련이 없다는 것도 학습"되어야 하기 때문에, 고양이 노드가 추가되고 고양이 사진이 추가되면 신경망 내의 모든 노드와 파라미터 값에 영향을 미친다. 따라서 기존 학습데이터와 고양이 학습 데이터 전체를 다시 학습시킬 수 밖에 없다.

딥러닝 4대 천왕
아래 사진 왼쪽부터 Yann LeCun, Geoffrey Hinton, Yoshua Bengio, Andrew Ng 교수님인데, 딥러닝 분야를 선도하는 4명의 교수님들이다. 대학교와 함께 페이스북, 구글, IBM, 바이두 등 기업에서도 같이 일하면서 학계와 업계를 이끌고 있다.

이상으로 딥러닝의 중요성을 부각시킨 3대 사건과 인공신경망의 단점을 극복하고 새로운 이름인 '딥러닝'으로 화려하게 부활한 사연, 딥러닝의 대표적인 모델인 CNN과 RNN, 그리고 장/단점 까지 알아보았다.
'IT정보' 카테고리의 다른 글
| [AI] 머신러닝 지도학습(Supervised Learning) , 비지도학습(Unsupervised Learning) 차이점과 장단점 (0) | 2022.03.30 |
|---|---|
| [AI] 인공 지능 , 머신 러닝, 딥 러닝 차이점이 무엇일까요? (0) | 2022.03.29 |
| 신기한 미래 유망 직업 10가지 (0) | 2022.03.27 |
| 로봇공학이란 (0) | 2022.03.25 |
| 배우기 좋은, 가장 인기 많은 프로그래밍 언어는? (0) | 2022.03.24 |